Christmas trees were burned at the beach. The Champlain Heights neighbourhood was developed. Vancouver submitted a bid for the 1976 Winter Olympic Games. Civic elections were held every two years. The Georgia Viaduct was replaced. Habitat I was held here. The federal Local Initiatives Program funded many labour-intensive projects.

Now you can easily explore all the issues discussed by City Council in the 1970s. We’ve made the minutes of Vancouver City Council meetings, along with the accompanying reports, searchable online.
WHAT’S AVAILABLE AND WHERE
Thanks to funding from the British Columbia History Digitization Program, we’ve digitized the 1970s City Council Minutes. The project included City Council meeting minutes (and the reports filed with the minutes) of both regular and special meetings held from 1970 through 1979. Special joint meetings with Burnaby and Richmond City Councils are included. Keyword-searchable PDF files have been made available through our online search. One file contains the minutes and reports for one meeting; there are 554 separate meetings.
We’ve also made these PDF files available as a subcollection on the Internet Archive. These files have been automatically converted to other formats, such as DAISY and EPUB, by the Internet Archive.
The Internet Archive search shown above (and our own online search) searches only the descriptive summaries for each set of minutes.

These summaries relate the topic to the relevant pages within the minutes. Usually they use the large, stamped page numbers given to an entire volume but sometimes the typed page numbers given to the minutes are used.

On the Internet Archive, you can search each set of minutes by keyword within the book reader. From our site, you need to download the PDF in order to keyword search.
WANT IT ALL?
We’ve made a PDF of all 23,812 pages (~480 MB) available in two places.
- Internet Archive. It’s too big for their online reader, but you can download using the “PDF” link in the left sidebar. https://archive.org/details/CouncilMeetingMinutes1970s
- On the City’s ftp site. ftp://webftp.vancouver.ca/archives/CouncilMeetingMinutes1970s.pdf
We’ve also made a smaller, plain text version available on the City’s Open Data Catalogue. It was created from the Optical Character Recognition (OCR) text that makes the PDF files searchable. Where the OCR text differs from the typed original, the original is always the authoritative record. The plain text version can be the basis for future mark-up of the text to make it more useable.
WATCH YOUR VOCABULARY
When searching, remember that these are all the original words used in the 1970s and some will not be the same as are used today. For example:
- There were no Councillors, only Aldermen (even the women!)
- There were references to “Cambie Bridge”, but most discussion was under the name “Connaught Bridge”
- B.C.’s “Liquor Distribution Branch” was called “Liquor Administration Branch”
- The City’s Information Technology Department was called the “Data Processing and Systems Division”
- Human Resources was called “Personnel Services”
- Imperial (miles) rather than metric (kilometres) measurements were used
- Emily Carr University was called “Vancouver School of Art” for most of the decade and renamed “Emily Carr College of Art” in 1978
The content is the official record, including the original typographical errors. We have not corrected original errors.
THE DIGITIZATION PROJECT
This was the largest text digitization project we’ve ever done.
First, we digitized all 23,812 pages in separate units by meeting. This resulted in an image of each page.
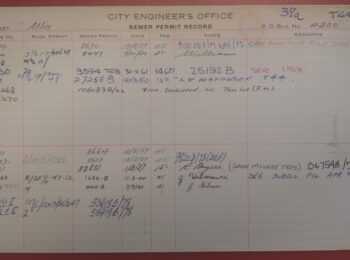
Next, we segmented the images to show which parts of the content were text, tables or images. We need this in order to tell the program which parts of the page to convert to text, and how. This will help to produce plain text that makes sense.

Next, we performed Optical Character Recognition on the segmented images, to produce searchable text. Trying to produce text in the image area shown above would result in a mess. Trying to produce text from a table without showing where the rows and columns belong would produce a page that is difficult or impossible to read.
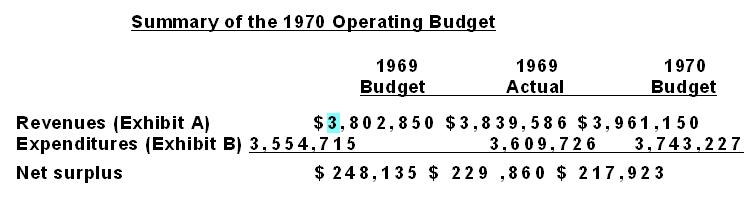



Finally, we proofread the OCR text to ensure it was accurate. Usually the program produced a high level of accuracy but sometimes the old typewriter fonts were hard to understand.


If you find an error we didn’t catch, please let us know. We will attempt to fix the plain text version as quickly as possible.
We are looking forward to your feedback on this project and to hearing about any projects in which you’ve used these records.
This digitization project was made possible by funding from the British Columbia History Digitization Program at the Irving K. Barber Learning Centre, University of British Columbia.