

We have long recognized the importance of increasing accessibility to our City Council Meeting Minutes series (COV-S31), from providing microfilm access copies in the 1970s to our early digitization effort back in 2013 using a Fujitsu document scanner. With limited resources and time, however, it has been challenging to sustain progress. This all changed in 2023 with the procurement of an Atiz BookDrive Mark 2 book scanner, and we are excited to highlight our revamped digitization workflow made possible by this newest addition to our fleet of scanning equipment.
Our early digitization effort involved disbanding the bound Council minutes volumes in order to run the pages through the Fujitsu scanner’s automatic feed. This is not ideal, as the binding serves an important purpose in maintaining the physical order of the pages and is also quite beautiful.

In comparison to our previous workflow, the biggest advantage of the new Atiz book scanner is that disbanding each Council minute book is no longer needed. Disbanding volumes was not only time-consuming, but additional archival supplies were also needed to rehouse the loose pages. Instead of feeding disbound pages into a document scanner, the Atiz book scanner has an adjustable cradle that can accommodate volumes of various sizes and thicknesses, allowing bound volumes to be digitized safely without altering the original binding. The glass V-platen in the book scanner is designed to gently hold down the opened pages and scan deeper into the gutter while keeping the pages in plane. The dual-camera imaging system, set up with two Canon EOS R5 mirrorless cameras, can capture both sides of an opened book in sequential order.


The high-resolution digital cameras can capture the minutes in high quality, full-colour images with less visual noise. This is a significant visual improvement from the grayscale images generated from the document scanner, as the full-colour images represent the physical records more faithfully.

Why does digitization take so long?
You may be wondering, even with the new book scanner, why does it still take so long to digitize the entire Council minutes series? The answer to this is multifaceted. While the preparatory step in disbanding the volume is eliminated and the overall workflow is streamlined, digitization is still a very labour-intensive process. As a trade-off in preserving the original binding, we are faced with other technical challenges when digitizing a three-dimensional object. Each image is captured by lifting the glass platen and manually turning the pages of the minute book, a task that is done painstakingly by our digitization technician. Also, as digitization moves through a volume, the position of the book will naturally shift. To maintain a similar field of view between all the digitized pages, foam supports are inserted underneath the book to finetune the positioning of the volume in relation to the cameras.

To further complicate the capture process, there are inherently many irregularities in how the original pages of the minutes were bound or even typed. Occasionally the text on the page appears at an angle or is missing entirely. Not only does this call for micro-adjustments during the capture process, but this also creates problems when performing optical character recognition (OCR), a feature that makes the image keyword searchable.

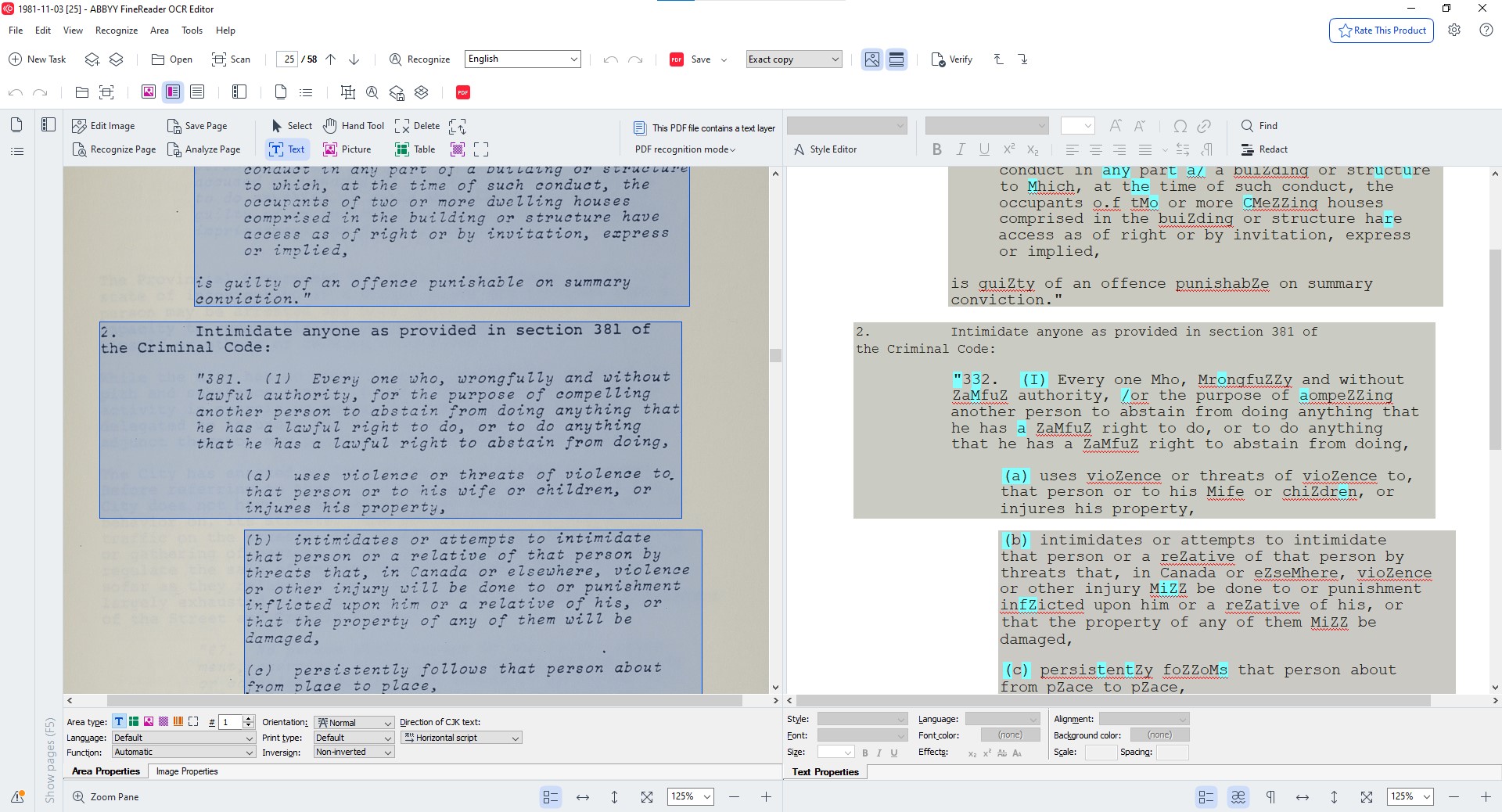
Since we last blogged about the OCR process, we have upgraded our ABBYY FineReader software to its latest version. The updated software has shown drastic improvements in character recognition accuracy, noticeably shaving off time in the workflow. We also simplified the OCR process with the decision to ease up on the granularity in segmentation and to focus our attention on ensuring specific keywords are captured. Segmentation is a step that identifies blocks of text to be interpreted and informs the software whether an area should be interpreted as text, image, or table. The digitization technician runs a first pass with the software’s automated segmentation feature, which is then checked and adjusted by an archival assistant. Once segmentation is complete, the software will analyze the entire document and interpret the characters.
Even with the latest advancements in OCR technology, the software still lacks the sophistication to accurately detect characters printed at an angle or decorative and handwritten fonts. For this reason, the archival assistant will review the automated OCR for quality control. As part of the revamped workflow, we are prioritizing the accuracy of legal addresses, bates numbers (the pre-printed sequential page numbers at the top of each page) and names of individuals and entities. These are useful keywords that correlate to the agenda items listed in the meeting description in our database and in our on-line Council index. By being a bit more forgiving in what we correct, we are spending less time on catching every single mis-recognized character and further streamlining the OCR process.
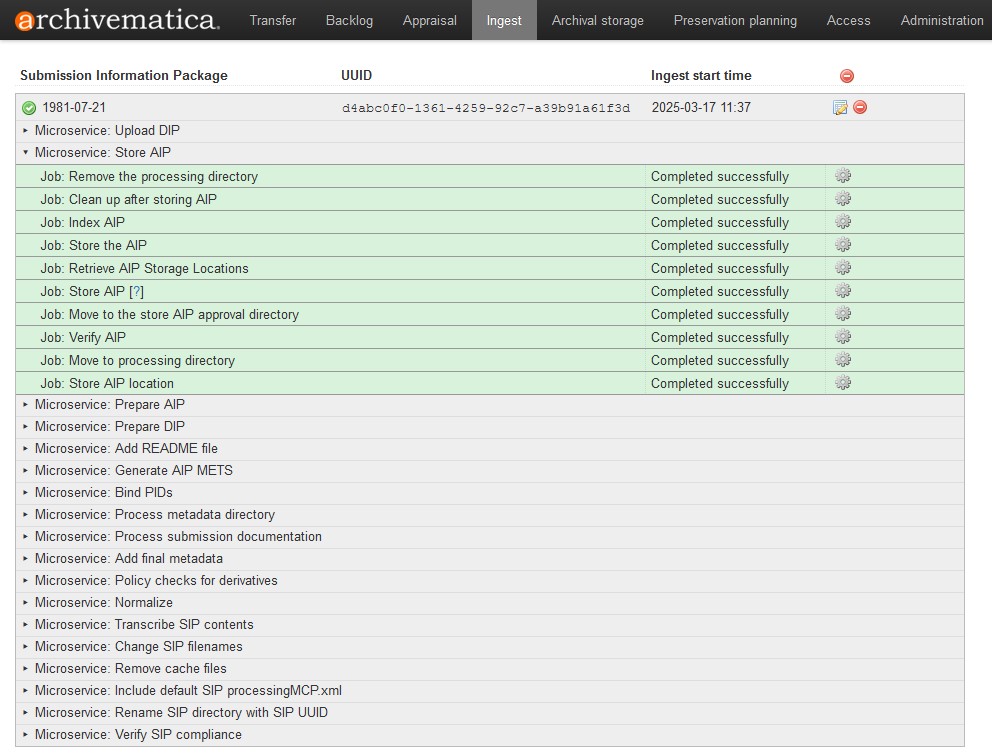
Once OCR and quality control are complete, the set of minutes with the embedded OCR text layer is exported as a PDF format that becomes the access copy. A multi-page TIFF file is also generated for each set of minutes and is designated as the preservation master copy based on current best digital preservation standards. The multi-page TIFF file is then packaged together with the PDF and transferred by a digital archivist or the digital conservator to our digital preservation system, Archivematica, which runs a number of processes on the files before sending them to a secure deep network storage location (as an Archival Information Package or AIP). After the ingest is completed successfully, Archivematica automatically uploads the PDF access copy (technically referred to as a Dissemination Information Package or DIP) to the corresponding file-level description on our online database.
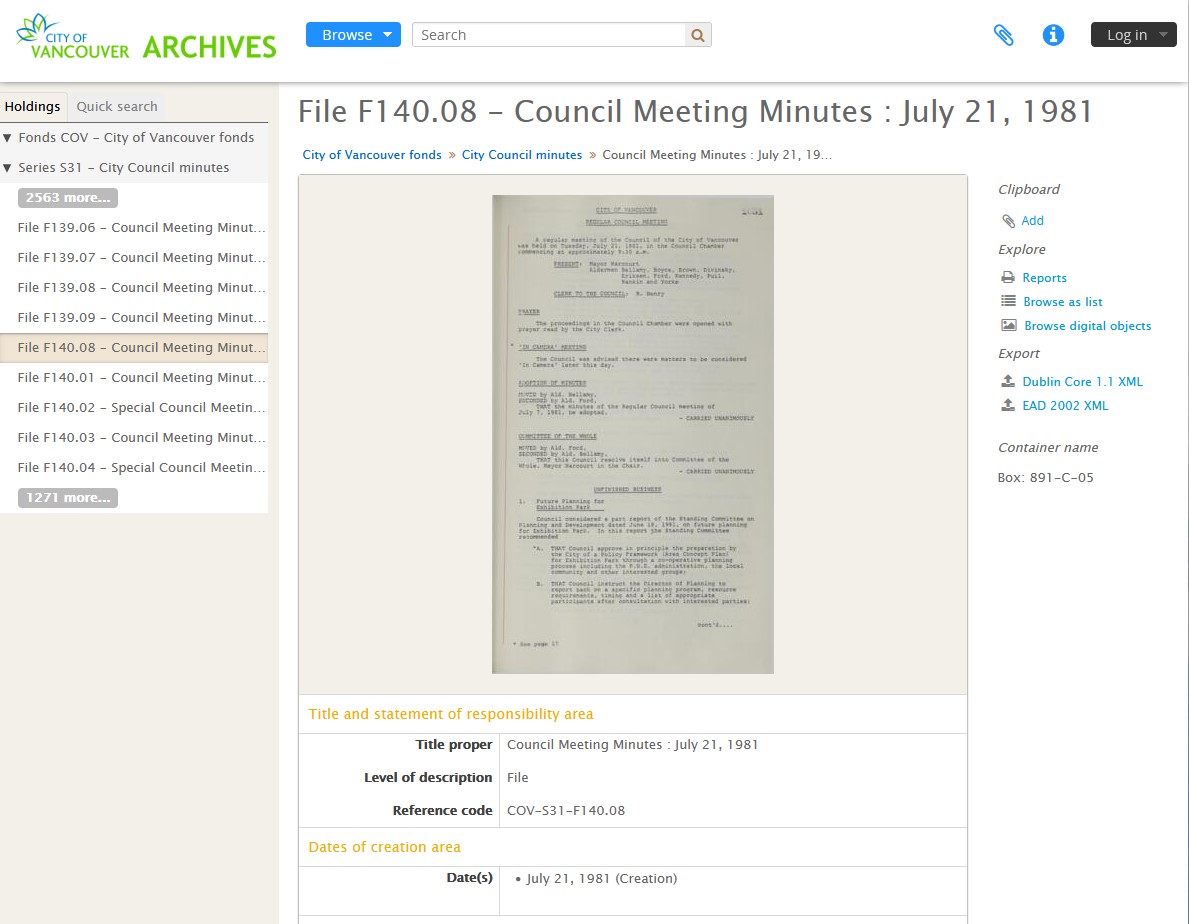
The digitization of Council meeting minutes is a laborious process, especially when taking into consideration that many of the minutes in the 1980s and more recent years are over a hundred pages long. That’s a lot of pages to capture and a lot of OCR to check, even with a simplified approach to the latter. After running a short pilot project to resolve technical challenges in the use of the new book scanner, we have since successfully digitized Council meeting minutes starting from 1980 to close to the end of 1981, the equivalent of 9 volumes and 4,500 pages of text. We are hoping to spend one to two days per week digitizing Council minutes and will continue to upload them onto our online database on a regular basis. So please check back often for updates or contact an archivist if you need further assistance using Council minutes for your research.





